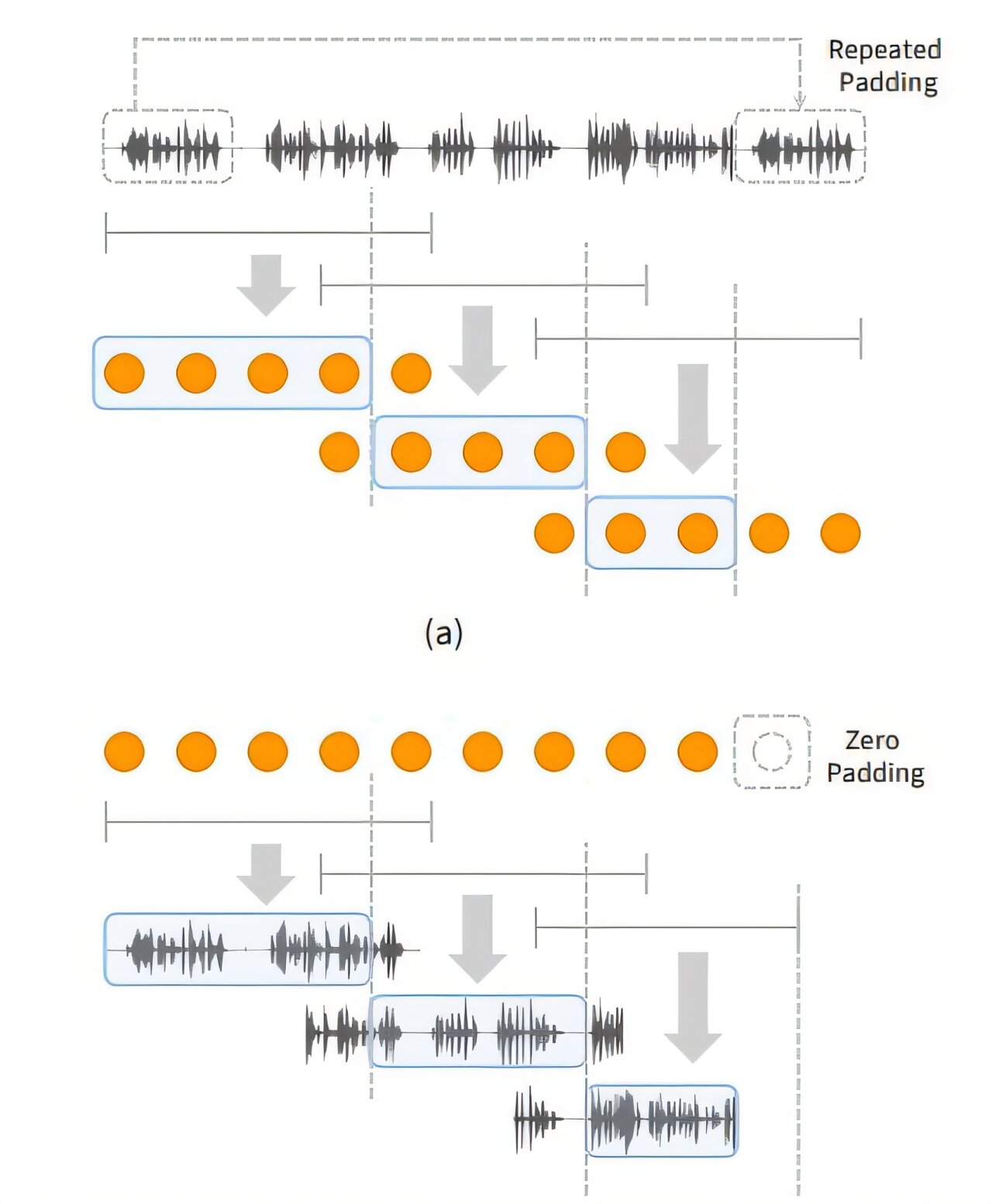
 tokenizing and (b) Decoding long-form speech to enable extrapolation in Decoding Lengths. Credit: Arxiv (2024). Doi: 10.48550/arxiv.2412.18603")
Windowing strategy for (a) tokenizing and (b) Decoding long-form speech to enable extrapolation in Decoding Lengths. Credit: arxiv (2024). Doi: 10.48550/arxiv.2412.18603
Recently, spoken language models (slms) have ben highlighted as next-generation technology that surpasses the limitations of text-based language models by learning from Understand and generate linguistic and non-linguistic information.
However, existing models show significant limitations in generating long-duration content required for podcasts, audiabooks, and voice assistants.
Ph.D. Candidate, Sejin Park, From Professor Yong Man Ro’s Research Team at the Korea Advanced Institute of Science and Technology’s (Kaist) School of Electrical Electric Electric Electric Electric Electric Electric Electric These limitation by developing “Speechssm,” which enables consistent and natural speech generation with constraints.
The work has been Published on the arxiv Preprint server and is set to be presented as at Icml (International Conference on Machine Learning) 2025.
A Major Advantage of Slms is their ability to direct process speech without intermediate text conversion, Leverapping the unique acoustic characteristics of Human speakers, Allowing for the Rapid Gennament High-Quality Speech even in Large-Scale Models.
However, existing models faced Difentials in Mainting Semantic and Speaker Consistency for Long-Duration Speech Due to Increased “Speech token Resolution” and Memory CON CON CON CAPTURING CHEN CAPTURING CHEN CAPTURING VINCELUTION ” Information by Breaking Down Speech Into Fine Fragments.
Speechssm Employers A “Hybrid Structure” That Alternately Places “Attention Layers” Focusing on Recent Information and “Recurrent Layers” That Remember the Overall Narrant Flow (Long-friendly. This allows the story to flow smoothly without losing coherence even when generating speech for a long time.
Furthermore, Memory Usage and Computational Load Do Not Increase Sharply With Input Length, Enableing Stable and Efficient Learning and the Generation of Long-Duration Speech.
Speechssm effectively processes unbounded speech sequences by dividing Speech Data Into Short, Fixed Units (Windows), Processing Each Unit Independent, And then Combining Themoning Themone Longing Long Speech.
Additionally, in the speech generation phase, it uses a “non-audio synthesis model (soundstorm), which rapidly generates Multiple parts at on Slowly Creating OR One word at a time, enabling the fast generation of high-quality speech.
While existing models typically evaluated short speech models of about 10 seconds, se jin park created new evaluation tasks for speech generation based on their self-benchmark dataset, “Librispeech-long,” Capable of generating up to 16 minutes of speech.
Compared to ppl (perplexity), an existing speech model evaluation To assess content coharence over time, and “N-MOS-T (Naturalness meaning meaning SCORENSION SCORE Over Time)
Through these new evaluations, it was confirmed that speech generated by the speechssm spokes model Consistently featured specific individuals mentationed in the initial prompt, and new challenges and elements Unfolded Naturally and Contextually Consistent, Despite Long-Duration Generation.
This contrasts sharply with existing models, which tended to easily lose their topic and exhibit repetition during long-duration generation.
Sejin park explained, “Existing spoken language models Had Limitations in Long-Durations in Long-Duration Generation, so our goal was to develop a spoke a spoken language model capiting Long-Duration SPECH FORACH FORACH FORACH FORACH FORACH FORACH FORACH
She added, “This research achievement is expected to great contribute to various types of voice content creation and voice ai fields likes like Voice Assesses, by Maintening CONTENTENT in Lonong Contexts and Responding more efficiently and qiykly in real time than existing methods. “
This research, with se jin park as the first author, was consumed in collaboration with Google Deepmind.
More information:
Se jin park et al, long-form speech generation with spoken language models, arxiv (2024). Doi: 10.48550/arxiv.2412.18603
Accompanying Demo: Speechssm publications,
Citation: Researcher develops ‘Speechssm,’ Opening Up Possibilites for a 24-His Voice Assistant (2025, July 4) Retrieved 5 July 2025 from https://techxplore.com/news/2025-07-Speechssm- Possibilites- Hour-i- Voice.html
This document is Subject to copyright. Apart from any Fair Dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.


